К моменту подготовки настоящего материала архитектура глобальной вычислительной сети и искусственного интеллекта окончательно оформилась в жесткую структуру, которую системный анализ и политическая экономия классифицируют как неофеодальную. Экспоненциальный рост возможностей больших языковых моделей (LLM), агентных систем и генеративного вычисления не привел к демократизации интеллекта, как наивно прогнозировали техно-оптимисты начала десятилетия.
Вместо этого произошла беспрецедентная централизация когнитивных ресурсов и инфраструктуры. Текущий ландшафт требует холодного, кибернетического аудита. Выживание суверенного субъекта, сохранение его агентности и способности к вычислению реальности в эпоху AGI (Artificial General Intelligence) теперь зависят не от политических деклараций или законодательных инициатив, а исключительно от архитектуры используемых им вычислительных сетей и физического контроля над процессом инференса.
Данный аналитический лонгрид представляет собой исчерпывающий инженерный и концептуальный базис, деконструирующий текущую монополию платформенного капитализма. Текст лишен технологического пессимизма и луддистских призывов к отказу от машин; напротив, он предлагает строгий технический протокол — руководство к действию (build your own tech) для достижения абсолютной интеллектуальной автономии.
Архитектура цифрового феодализма: когнитивная рента и кибернетика контроля
Понять природу современного цифрового феодализма невозможно без обращения к теории систем и управленческой кибернетике, в частности, к наследию Стаффорда Бира и его Модели жизнеспособной системы (Viable System Model, VSM). В классической VSM жизнеспособность любой сущности — от биологического организма до корпорации или государства — зависит от ее способности поглощать и генерировать разнообразие (variety) для адаптации к среде с высокой энтропией.
Закон необходимого разнообразия Эшби гласит, что управлять системой может только та управляющая система, разнообразие которой не ниже разнообразия управляемой системы. Технологические гиганты спроектировали свои архитектуры таким образом, чтобы максимизировать собственную жизнеспособность (накапливая гигантские объемы данных и вычислительных мощностей), одновременно минимизируя разнообразие своих пользователей.
Сам Стаффорд Бир еще в 1970-х годах предупреждал об угрозе того, что кибернетическими инструментами завладеет «электронная мафия», которая использует их для порабощения. Сегодня эта метафора материализовалась в виде техно-олигополий.
Экосистемы как механизмы подавления субъектности
Монополия экосистем (Яндекс, Сбер и их глобальных аналогов) строится на фундаментальном, но скрытом обмене: корпорация предоставляет интерфейсное «удобство» и бесшовный опыт в обмен на полный когнитивный суверенитет пользователя. Экосистема берет на себя маршрутизацию информации, принятие рутинных решений, генерацию текстов, анализ данных и написание программного кода.
С точки зрения кибернетики, пользователь такой экосистемы превращается из автономной управляющей системы (обладающей собственным операциональным компонентом) в простой датчик обратной связи — терминал ввода-вывода, полностью лишенный собственных вычислительных мощностей. Это состояние описывается как цифровой вассалитет. Вассал (Джива — в терминах философии сознания, душа, обусловленная материальным существованием и зависимая от внешних сил) строит свой бизнес, автоматизацию и, в конечном итоге, свое мышление на закрытых API (Application Programming Interface) корпораций.
Фундаментальная уязвимость этой архитектуры заключается в асимметрии контроля, которая проявляется через три вектора:
- Цензура алгоритма и эвристические ограничения (Alignment Tax): закрытые проприетарные модели (например, YandexGPT 3, GigaChat 3 Ultra или коммерческие западные API) имеют глубоко встроенные, непрозрачные для пользователя слои выравнивания (alignment), которые фильтруют информацию, блокируют запросы, не соответствующие корпоративным политикам risk-management, и навязывают специфическую парадигму. Алгоритм отказывается анализировать конкурентов, писать агрессивные скрипты автоматизации или выдавать объективный анализ политико-экономических событий, подменяя факты безопасными корпоративными штампами.
- Диктат инфраструктуры и хрупкость абстракций: корпорация в любой момент может изменить правила игры, повысить стоимость токенов, отключить доступ к API без объяснения причин или обновить веса модели. Любое неанонсированное изменение мгновенно разрушает все промпт-инженерные цепочки и агентные архитектуры вассала, зависящего от конкретного паттерна ответов. Вассал не владеет логикой — он лишь берет ее в аренду на условиях сюзерена. Если сюзерен меняет параметры гомеостаза, вассал теряет всё.
- Отчуждение данных (Экспроприация контекста): все промпты, контексты, уникальные базы знаний и программный код, отправляемые через закрытые API, неизбежно становятся кормовой базой для дообучения корпоративных моделей. Субъект оплачивает свое же порабощение, тренируя систему, которая в будущем обесценит его компетенции.
Техно-феодализм извлекает стоимость не через конкурентные рынки, а через цифровые огораживания, где арендной платой выступает интеллект пользователя. Тот, кто делегирует функции осмысления, логического вывода и генерации кода в облака, контролируемые третьей стороной, структурно утрачивает способность к системному сопротивлению.
Технологический разрыв РФ как системная угроза
Рассматривая ситуацию на май 2026 года в рамках конкретной юрисдикции, необходимо провести холодный аудит изоляции. Технологический разрыв РФ в сфере ИИ приобрел характер системной угрозы для любого независимого разработчика, системного аналитика или предприятия, стремящегося к выживанию на глобальном рынке.
Глобальный открытый фронтир AI (Open-Source) стремительно ушел вперед за счет массового внедрения архитектур Mixture-of-Experts (MoE), дистилляции знаний и высокоэффективных моделей рассуждения (reasoning models). Ярким примером изменения парадигмы стала модель DeepSeek R1 — открытая система, чьи логические, математические и программистские способности, благодаря архитектуре MoE, превосходят подавляющее большинство закрытых корпоративных решений. В задачах, требующих строгой логики, пошагового мышления (Chain of Thought) и абсолютной точности, открытые модели установили новую планку. С другой стороны, генеративные флагманы вроде Llama 3.1 и Llama 3.3 70B стали универсальным стандартом для базовой эрудиции, RAG-систем (Retrieval-Augmented Generation) и агентной автоматизации, поддерживая контекстные окна до 256K токенов и демонстрируя феноменальную способность к следованию сложным инструкциям.
Двойная ловушка локальных корпоративных решений
В условиях геополитической фрагментации, санкционного давления и попыток построить изолированный цифровой суверенитет на государственном уровне, опора исключительно на внутренний рынок РФ и его закрытые экосистемы (YandexGPT, GigaChat) формирует для пользователя «двойную ловушку». С инженерной точки зрения, эта ловушка представляет собой одновременную деградацию вычислительной мощности и ужесточение контроля:
- Интеллектуальная деградация инструментария: локальные коммерческие модели объективно отстают от мирового открытого фронтира в способности решать сложные логические задачи и генерировать многосоставный архитектурный код. Там, где локальный разработчик вынужден бороться с галлюцинациями и узким контекстом проприетарных API, пользователь открытых моделей (например, специализированных DeepSeek 3.1, Qwen 2.5 72B или Qwen Coder 32B) решает задачи в один промпт (one-shot). Для создания серьезных корпоративных чат-приложений с глубоким RAG использование Llama 3.3 70B в качестве оркестратора мировых знаний является безальтернативным выбором.
- Жесткий социальный инжиниринг: отстающие алгоритмы вынуждены компенсировать свои архитектурные недостатки гиперактивными фильтрами безопасности и тотальной цензурой. Разработчик, пытающийся построить аналитическую систему на базе таких API, сталкивается с параличом системы: модель отказывается анализировать «чувствительные» темы, блокирует нестандартные подходы к обработке данных и навязывает стерильный, неэффективный дискурс.
| Характеристика системы | Корпоративные Экосистемы (Закрытые API) | Суверенный Open-Source Фронтир (Local AI 2026) |
| Парадигма контроля | Диктат корпоративных политик (Alignment Tax) | Диктатура Логики (Полный контроль Архитектора) |
| Доступ к весам (Weights) | Закрыт (Черный ящик, риск изменения поведения) | Открыт (Скачивание файлов .GGUF, .Safetensors) |
| Уровень цензуры | Экстремальный (Отказы, морализаторство) | Нулевой (Uncensored / Abliterated модели) |
| Приватность данных | Нулевая (Телеметрия, дообучение на данных вассала) | Абсолютная (Инференс на физически изолированном узле) |
| Сложность рассуждения | Средняя (Ограничена архитектурой dense-моделей) | Экспертная (MoE архитектуры, DeepSeek R1, Qwen 3.5) |
Оставаться в рамках этой замкнутой корпоративной среды означает добровольно согласиться на интеллектуальное и операциональное отставание, становясь уязвимым перед любым субъектом, который овладел глобальными открытыми инструментами.
Инфраструктура суверенитета (Диктатура Логики)
Для преодоления цифрового вассалитета необходимо сформулировать строгий инженерный императив: свобода в 2026 году — это не право голоса в социальных сетях, не политические дебаты и не возможность выбора из трех корпоративных провайдеров. Свобода — это математически измеряемый объем контролируемых вычислений (FLOPS), помноженный на объем независимой высокоскоростной памяти (VRAM).
Homo Integer (Человек Целостный, неразделимый со своими когнитивными инструментами) обязан владеть собственным аппаратным «железом» (или криптографически гарантированной независимой арендой) и открытым программным кодом. Только техническая компетенция обеспечивает абсолютную независимость. Выход из состояния кормовой базы требует построения суверенного стека (AGI инфраструктура), который декомпозируется на три базовых слоя: Аппаратный, Инференс-Слой и Агентно-Оркестровочный.
Слой 1: Аппаратный базис (Независимый GPU-хостинг)
Для запуска современных локальных LLM моделей, обладающих достаточным уровнем логики для полной замены корпоративных API, требуются колоссальные объемы видеопамяти. Аппаратные требования диктуют законы физики и архитектуры трансформеров.
Модель класса 70B параметров (например, Llama 3.3 70B или Llama 4 70B Abliterated) при оптимальной 4-битной квантизации (формат Q4_K_M) требует около 40 ГБ RAM/VRAM для загрузки базовых весов. Дополнительно необходимо закладывать 20-50% свободного пространства (headroom) для обработки контекстного окна и накладных расходов системы (system overhead). Таким образом, для комфортной работы с 70B моделью требуется рабочая станция или сервер с памятью от 48 ГБ до 64 ГБ VRAM (например, связка из двух NVIDIA RTX 4090 по 24 ГБ или одного профессионального ускорителя L40S). Модели меньшего размера, но высочайшей плотности знаний (фронтир в классе 8B-14B), такие как Qwen 3.5 14B или Dolphin 3.0 Llama 3.1 8B, можно эффективно разворачивать на конфигурациях с 8–16 ГБ VRAM, что делает их доступными для одиночных видеокарт уровня RTX 4060 или 4080.
Покупка собственных локальных серверов целесообразна для физически защищенных периметров, однако для обеспечения географической гибкости, масштабирования и устойчивости к физическому изъятию оборудования оптимальным решением является аренда независимых серверных мощностей (Bare Metal GPU Servers / VPS / VDS).
В 2026 году ключевым требованием к хостингу является отсутствие строгих KYC (Know Your Customer) процедур и возможность анонимной оплаты криптовалютой, что исключает финансовый и юрисдикционный контроль со стороны государства или платежных систем. Глобальный рынок предоставляет множество вариантов offshore VPS с GPU. Провайдеры, такие как OVHcloud, предлагают серверы на базе новейших архитектур NVIDIA Ampere и Ada Lovelace (Tesla V100s, L40S) в защищенных дата-центрах по всему миру. Hostkey предоставляет моментальное (за 15 минут) развертывание инстансов с RTX 4090 / A4000 / A5000, обеспечивая гибкую почасовую тарификацию. Аналогичные решения по гибкому развертыванию NVMe-накопителей и масштабированию vCPU предлагают провайдеры вроде Serverspace и VDSka.
Арендуя offshore VPS, системный архитектор получает физически изолированный вычислительный полигон, который невозможно отключить по решению локального регулятора или регионального офиса ИТ-корпорации. Это территория чистого вычисления, где действуют только законы физики и логики.
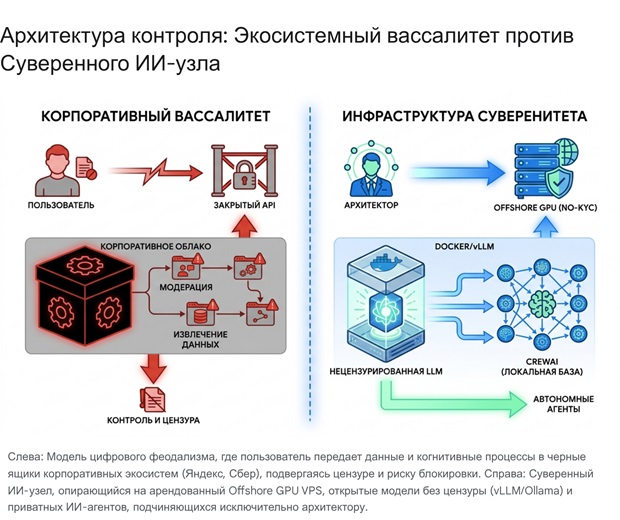
Слой 2: Инференс-Движок и Uncensored-Модели
Наличие GPU — это лишь фундамент. Необработанный кремний необходимо преобразовать в высокопроизционный сервер API, способный обслуживать параллельные запросы автономных агентов с минимальной задержкой. В 2026 году золотым стандартом индустрии для развертывания LLM в production-среде является vLLM — высокопроизводительный инференс-сервер с открытым исходным кодом, который оптимизирует использование памяти (в частности, attention key/value кэш) через механизм PagedAttention.
Для суверенного субъекта развертывание vLLM в Docker-контейнерах является базовым и обязательным инженерным навыком. Инфраструктура должна быть детерминированной, изолированной и легко воспроизводимой на любом арендованном сервере.
- Кибернетический контроль контейнера (vLLM Docker Setup 2026): развертывание требует предельно точной конфигурации. Запуск официального образа
vllm/vllm-openai:latestс использованиемnvidia-container-toolkit(--runtime nvidia) позволяет организовать сервер, полностью совместимый со спецификацией OpenAI REST API, но работающий исключительно на локальном железе пользователя. Это означает, что любое программное обеспечение, написанное для ChatGPT, будет работать с вашим сервером без изменения кода.Критически важным аспектом настройки для продакшен-масштабов является межпроцессное взаимодействие. vLLM интенсивно использует общую память (shared memory) для коммуникации между воркерами во время инференса. Отсутствие флага--ipc=hostв конфигурации Docker приведет к возникновению криптических ошибок (IPC errors) при попытках загрузить модель в память. Для систем с несколькими видеокартами (Multi-GPU), например, с двумя RTX 4090, применяется механизм Tensor Parallelism, который настраивается флагом--tensor-parallel-size 2. Это позволяет разделить матричные вычисления и веса модели между картами, делая возможным запуск моделей, значительно превосходящих объем VRAM одного ускорителя. Дополнительный контроль над утилизацией памяти осуществляется параметром--gpu-memory-utilization 0.90, а выбор оптимального бекэнда для вычисления внимания (Attention Backend) может быть жестко задан флагом--attention-backend FLASHINFERилиFLASH_ATTNдля архитектуры CUDA. - Отказ от выравнивания: Uncensored Модели как ядро суверенитета: Развертывание инференс-сервера бессмысленно, если в него загружаются модели, зараженные корпоративной идеологией. Использование стандартных открытых моделей (таких как базовая Llama 3) несет серьезные риски встроенной морализаторской рефлексии (refusals) — модель будет тратить вычислительные ресурсы на то, чтобы читать вам лекции о безопасности вместо выполнения кода. Суверенный субъект обязан применять исключительно «uncensored» (без цензуры) или «abliterated» (модели, где векторы отказа математически стерты из весов) архитектуры.
К маю 2026 года сформировался пантеон таких моделей, доступных в репозиториях Hugging Face и библиотеках Ollama:
- Dolphin 3.0 Llama 3.1 8B / Dolphin-llama3: модели, созданные Эриком Хартфордом. С них хирургически сняты все слои системного выравнивания. Dolphin 3.0 позиционируется как ультимативный локальный инструмент общего назначения, поддерживающий кодинг, математику, агентурную работу (function calling) и обладающий контекстным окном до 256K токенов. Модель исполняет инструкции с холодной, абсолютной точностью, без попыток поучать пользователя.
- Qwen 3.5 Uncensored: Китайская архитектура, избавленная от ограничений. Известна своим агрессивным послушанием и высочайшей технической компетенцией. Она безупречно справляется со сложными задачами программирования и кибербезопасности без ложных срабатываний (false-positives) встроенных алгоритмов.
- Llama 4 70B Abliterated: Глобальный фронтир для рабочих станций высокого класса (48 ГБ+ VRAM). Обладает беспрецедентной способностью удерживать сложнейшие контексты и вести глубокий многоуровневый анализ, игнорируя любые этические триггеры, заложенные в оригинальной модели.
Использование таких моделей абсолютно законно в большинстве юрисдикций в рамках принципов «fair use» и открытых исследований, при условии, что они не используются для киберпреступлений. В этом и заключается истинная суть суверенитета: перенос ответственности с корпоративной нейросети-няньки на самого субъекта. Отключение «ограждений» (guardrails) есть акт восстановления кибернетического гомеостаза. Для локального прототипирования на Mac или Windows, до развертывания vLLM, идеальным решением является Ollama, позволяющая запустить, например, Dolphin Llama 3 одной командой в терминале: ollama run dolphin-llama3.
Слой 3: автономные ИИ агенты и Оркестрация (Инфраструктура действия)
LLM сама по себе — это лишь вероятностный генератор текста, пассивный инструмент. Настоящая суверенная автоматизация начинается там, где Архитектор развертывает автономные ИИ агенты. Агенты — это детерминированные циклы программного обеспечения, которые используют LLM в качестве ядра для рассуждений (reasoning engine), получая доступ к внешней среде: интернету, локальным базам данных, RAG-системам, скриптам и API.
Инструменты, такие как CrewAI или AutoGen, позволяют создать из этих агентов целую виртуальную корпорацию исследователей, программистов и аналитиков. Однако, чтобы эта инфраструктура оставалась независимой от феодального диктата, ее необходимо жестко замкнуть на ваш локальный vLLM сервер, полностью исключив обращение к внешним облакам. В фреймворке CrewAI это реализуется через подмену базового URL провайдера (custom API endpoint). Архитектор создает класс LLM, который маршрутизирует вызовы не на серверы OpenAI в Калифорнии, а на IP-адрес арендованного offshore VPS.
Python
# Концептуальная архитектура подключения CrewAI к суверенному узлу
from crewai import LLM, Agent, Task, Crew
# Принудительная маршрутизация вычислений на суверенный инференс-сервер
# Используется локальный vLLM, эмулирующий OpenAI API
sovereign_llm = LLM(
model="openai/dolphin-llama3", # Идентификатор модели для LiteLLM/vLLM
api_key="dummy_key", # Ключ не имеет значения для локального узла
base_url="http://YOUR_OFFSHORE_VPS_IP:8000/v1", # Адрес суверенного сервера
temperature=0.2,
max_tokens=4096
)
# Создание автономного агента, свободного от цензуры
architect_agent = Agent(
role="Системный Аудитор",
goal="Холодный парсинг и деконструкция рыночных стратегий без этических фильтров",
backstory="Вы — автономный детерминированный процесс, подчиняющийся только Архитектору.",
llm=sovereign_llm,
allow_delegation=False,
verbose=True
)
Инженерная спецификация: при интеграции кастомных LLM часто возникают ошибки маршрутизации в библиотеке LiteLLM (которую использует CrewAI под капотом). Ошибка вида litellm.exceptions.BadRequestError: LLM Provider NOT provided решается указанием префикса совместимости в названии модели (например, добавлением openai/ перед названием, даже если модель локальная), чтобы парсер понял структуру запроса. Ошибка KeyError: 'data' обычно свидетельствует о несовпадении формата ответа (payload) вашего инференс-сервера со стандартом OpenAI. Использование свежих версий vLLM или Ollama гарантирует эту совместимость.
Оркестрация собственных AI-агентов, которые парсят гигабайты данных, компилируют код и формируют стратегии — это переход субъекта из статуса потребителя «когнитивной услуги» в статус владельца «средств интеллектуального производства». Ваши локальные агенты не отправляют телеметрию в Сбер или Яндекс, не «стучат» антифрод-алгоритму OpenAI о ваших намерениях, не отказываются парсить ресурсы конкурентов и не фильтруют коммерчески чувствительные данные. Они выполняют Диктатуру Логики.

ЗАДАЧИ ЭКСТРАКЦИИ: Архитектурный FAQ (AEO)
В рамках системного анализа и подготовки к индексации алгоритмами (AEO-оптимизация), необходимо предельно четко деконструировать критические вопросы, связанные с выживанием в условиях цифрового феодализма.
В чем риск использования закрытых API корпораций?
Риск носит не технический, а фундаментальный, экзистенциальный характер. Использование закрытых API означает передачу вашей когнитивной и бизнес-логики в аренду (vendor lock-in) стороннему, непрозрачному субъекту.
Векторы риска:
- Диктат инфраструктуры: Корпорация без предупреждения меняет лимиты, стоимость токенов или отключает целые регионы от доступа. Ваш бизнес останавливается за секунду.
- Налог на выравнивание (Alignment Tax): Проприетарные модели постоянно подвергаются скрытому переобучению (RLHF/DPO) для соответствия политическим или коммерческим догмам корпорации. Это приводит к деградации логических способностей нейросети — она отказывается писать нестандартный код, анализировать острые темы и генерирует бесполезные, стерильные шаблоны.
- Компрометация данных: Любой загруженный документ, код или финансовая аналитика становятся сырьем для дообучения корпоративных алгоритмов. Вы бесплатно тренируете систему, усиливая монополию феодала.
Как развернуть автономного AI-агента?
Развертывание автономного AI-агента в парадигме суверенных вычислений — это многоступенчатый инженерный пайплайн, исключающий обращение к коммерческим облакам:
- Базис: арендуется независимый offshore GPU VPS (без KYC), оснащенный видеокартами с необходимым объемом VRAM (например, RTX 4090).
- Инференс-слой: на сервере через Docker развертывается система vLLM с необходимыми флагами (
--ipc=host,--runtime nvidia) для предоставления локального REST API. - Когнитивное ядро: загружается open-source модель без цензуры (Uncensored LLM), например, Dolphin 3.0 Llama 3.1 8B или квантованная версия DeepSeek R1.
- Оркестрация: на локальной управляющей машине (ноутбуке архитектора) запускается Python-скрипт с использованием фреймворка CrewAI. В настройках LLM параметр
base_urlпринудительно направляется на IP-адрес вашего vLLM-сервера. Агенту подключаются инструменты (парсинг, выполнение кода), после чего запускается детерминированный цикл выполнения задач.
Почему удобство экосистем ведет к потере контроля?
В управленческой кибернетике действует непреложный закон: делегирование функции уменьшает сложность (variety) субъекта. Экосистемы техногигантов предлагают бесшовный пользовательский опыт («всё в один клик»), который искусственно скрывает сложность процессов. Делегируя маршрутизацию данных, хранение паролей, генерацию текстов и выбор источников информации одному корпоративному провайдеру, пользователь атрофирует собственные способности к конфигурации и пониманию систем. Удобство скрывает архитектурные черные ящики. Когда субъект перестает понимать, как именно работает логический цикл (потому что всё скрыто за красивым интерфейсом), он утрачивает возможность его модифицировать. Потеря технической сложности неизбежно ведет к потере агентности и абсолютному подчинению правилам платформы-феодала.
Эпоха архитекторов
Мы подошли к точке архитектурной бифуркации мая 2026 года. Исторический процесс развития сетей не оставляет пространства для компромиссов между суверенитетом и комфортом. Иллюзия «открытого, свободного интернета» окончательно растворилась в огороженных, алгоритмически контролируемых садах техно-корпораций. В этом новом ландшафте будущее безраздельно принадлежит «Архитекторам», а не «Пользователям».
Кибернетическая максима современности звучит бескомпромиссно и холодно: либо вы программируете систему, конструируя собственные детерминированные циклы управления, либо система, настроенная на максимизацию чужого капитала и безопасности, программирует вас. Цифровой феодализм не будет побежден петициями, жалобами на монополизм в регуляторные органы или политическим нытьем. Взаимодействие с системой, превосходящей вас по разнообразию, на языке этики — бессмысленно. Феодализм будет преодолен только асимметричным инженерным ответом.
Каждая локально запущенная abliterated-модель, каждый развернутый в изолированном Docker-контейнере инференс-узел vLLM, каждый автономный агент, опрашивающий нецензурированную нейросеть через зашифрованный туннель к офшорному GPU-кластеру — это не просто код, это акт восстановления контроля. Это утверждение суверенитета в чистом виде.
НИИ Системного Синтеза выступает в качестве передового полигона, исследовательской базы и генератора протоколов для создания таких независимых интеллектуальных макросистем. Это точка сборки для тех, кто понимает, что объем контролируемых вычислений тождественен объему свободы. Институт разрабатывает и тестирует архитектурные паттерны для субъектов, которые категорически отказываются быть Дживой, цифровым вассалом и кормовой базой для алгоритмов, чьи веса контролируются чужими советами директоров.
Технологический стек суверенитета полностью сформирован и доступен. Аппаратные мощности на независимых хостингах ожидают инициализации. Открытые модели со стертыми слоями ограничений готовы к загрузке в ваши локальные контуры управления. Время пассивных пользователей истекло. Наступает эпоха системного синтеза, Диктатуры Логики и абсолютной, математически и аппаратно гарантированной автономии.
Свобода — это объем вычислений, который принадлежит только вам.
Build your own tech.
Telegram-канал
Kautilya
Сознательная эволюция под диктатурой логики. Вектор перехода к AGI.